After running one of the world’s most popular link analysis platforms for over a decade, we’ve accumulated something unprecedented in the AI training data landscape: the largest disavow dataset outside of Google itself. This treasure trove of real-world manipulation evidence represents millions of webmaster decisions about which sources were toxic enough to actively reject—and we’re using it as a powerful proxy for detecting human patterns of intent to manipulate across digital content.
The Challenge of Detecting Intent to Manipulate in AI Training
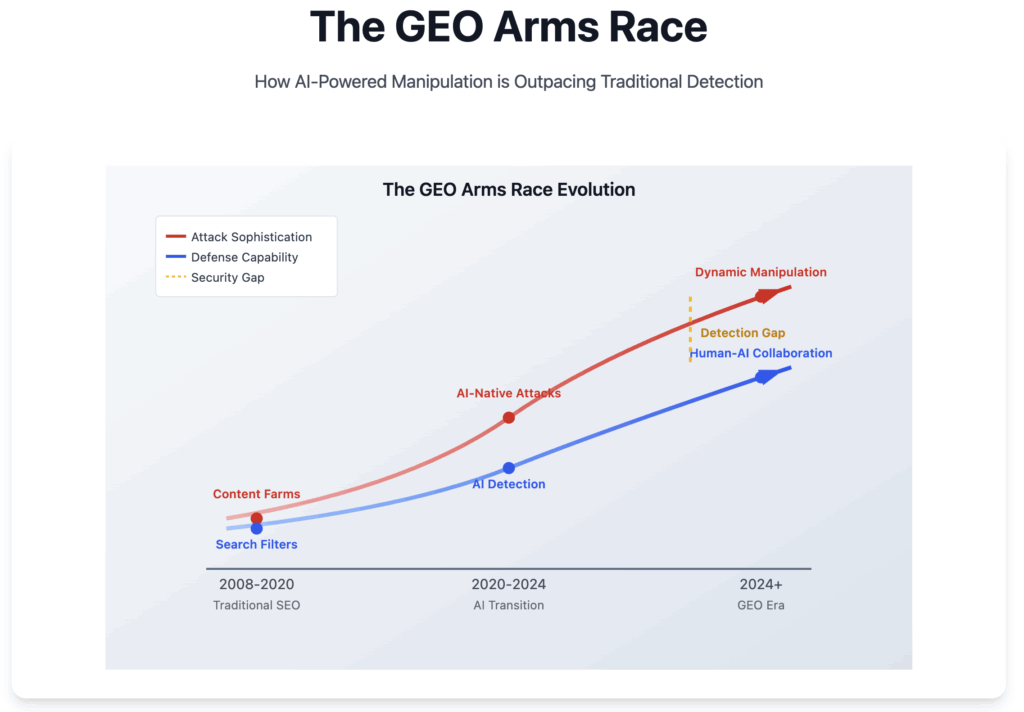
As AI companies race to train increasingly sophisticated language models, they face a critical challenge that goes beyond simple content quality: how do you detect when humans deliberately created content with intent to manipulate? Traditional approaches rely on surface-level signals—domain authority scores, publication dates, or basic spam detection. But these methods fundamentally miss the most insidious threat: sophisticated human actors who understand how to create content that appears legitimate while serving manipulative purposes.
When AI models are trained on content created with manipulative intent, they don’t just risk producing inaccurate information—they learn the very patterns that human manipulators use to deceive. The model absorbs not just the false information, but the sophisticated techniques used to make that information appear credible.
A Proxy for Human Manipulation Patterns
Our disavow dataset represents something far more valuable than a simple catalog of “bad” websites—it’s a record of human decisions made when people recognized they were being targeted by deliberate manipulation campaigns. When someone adds a domain to their disavow file, they’re essentially saying: “I believe this source was created or operated with intent to manipulate the system and harm my site’s credibility.”
These decisions capture the moment when humans identified patterns of manipulative intent that automated systems initially missed. The disavowed sources often represent sophisticated human efforts: content farms designed to look legitimate, link networks carefully constructed to appear natural, and manipulation campaigns that required human planning and coordination to execute.
This makes our dataset a unique window into how humans actually attempt to manipulate digital systems—and crucially, how other humans learn to recognize and reject those attempts.
Decoding the Fingerprints of Manipulative Intent
Over the past decade, we’ve observed patterns in human manipulation behavior that would be impossible to detect through traditional content analysis:
Evolution of Deception Tactics: We can track how human manipulators adapt their strategies over time, moving from crude spam to sophisticated content that mimics legitimate publishing. Our data reveals the learning curve of malicious actors.
Coordinated Manipulation Networks: By analyzing which sources were disavowed together, we can identify when multiple domains were part of coordinated human campaigns designed to appear independent while serving the same manipulative goals.
Psychological Manipulation Patterns: Certain content structures and presentation styles consistently appear in disavowed sources, revealing the psychological techniques humans use to make manipulative content appear trustworthy.
Intent Versus Accident: We can distinguish between sources that became problematic due to neglect or poor judgment versus those that show clear patterns of deliberate manipulation—the difference between incompetence and malicious intent.
Training AI to Recognize Human Deception Patterns
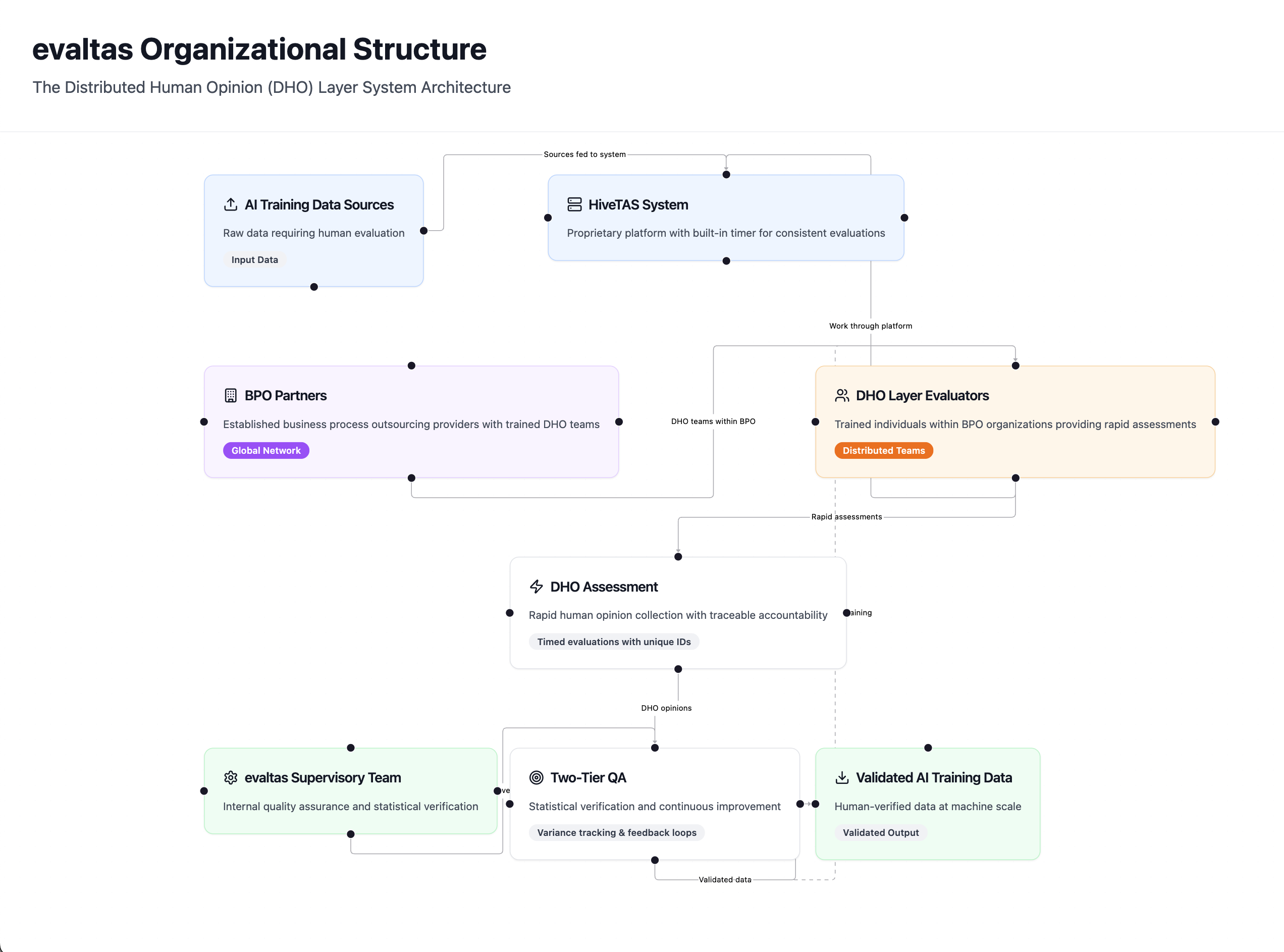
At Evaltas.ai, we use this dataset as one component in our broader approach to understanding trust and manipulation. The disavow data serves as a powerful proxy for detecting human patterns of intent to manipulate—teaching our models to recognize the subtle signatures that indicate when content was created with deceptive purposes.
Our AI models learn from millions of examples where humans successfully identified manipulative intent that automated systems initially missed. The models can detect the sophisticated techniques that malicious actors use: the careful balance of appearing legitimate while serving manipulative goals, the coordination patterns that indicate organized deception campaigns, and the psychological manipulation tactics embedded in content structure and presentation.
This goes beyond simple content filtering—we’re teaching AI systems to think like human experts who have learned to spot the difference between genuine content and sophisticated manipulation attempts.
Beyond Pattern Recognition: Predicting Manipulative Intent
The real breakthrough isn’t just in identifying current manipulation—it’s in predicting when content shows early signs of manipulative intent. Our models can analyze content characteristics and identify patterns that match the fingerprints of sources that humans later recognized as deliberately deceptive.
We can assign risk scores based on similarity to known manipulation patterns: “This content exhibits structural and stylistic characteristics that appeared in 78% of sources that humans later identified as manipulative campaigns” provides actionable intelligence that goes far beyond surface-level quality metrics.
This predictive capability helps AI companies identify not just poor-quality content, but content that may have been specifically designed to deceive AI training processes.
Understanding Human Deception at Scale
While other approaches try to identify manipulation through automated content analysis, we’re working with evidence of human-to-human recognition of deceptive intent. Our trust assessments incorporate the collective wisdom of millions of people who learned to identify when they were being deliberately targeted by manipulation campaigns.
This creates a fundamental advantage: instead of trying to reverse-engineer what manipulation looks like, we can learn from the accumulated experience of humans who became expert at recognizing it. As manipulation tactics evolve, our understanding evolves with them, capturing new patterns of human deceptive intent as they emerge.
Implementation as Part of Comprehensive Trust Assessment
Integrating this manipulation detection intelligence into AI training workflows represents just one component of our approach to understanding trust. The disavow dataset helps AI companies:
- Identify deliberate deception patterns based on historical human recognition of manipulative intent
- Reduce sophisticated false positives by distinguishing between content that appears low-quality versus content designed to deceive
- Provide manipulation risk scores that complement other trust assessment mechanisms
- Predict emerging deception tactics by identifying content that matches early-stage patterns of campaigns humans later recognized as manipulative
This manipulation detection capability works alongside other trust signals to provide a more complete picture of content reliability and intent.
Towards AI That Understands Human Deception
This dataset represents one piece of a larger puzzle in building AI systems that can understand human intent and deception. By learning from real-world examples of how humans recognize and respond to manipulative intent, AI companies can train models that go beyond surface-level content analysis to understand the deeper patterns of human deception.
As the AI industry matures, the ability to detect not just poor content but deliberately deceptive content will become increasingly critical. The challenge isn’t just filtering out mistakes or low-quality information—it’s identifying when humans have specifically crafted content to deceive AI training processes.
Our disavow dataset provides a unique window into this human dimension of deception, complementing other approaches to create more robust trust assessment systems.
The Human Element in AI Trust
The stakes for understanding manipulative intent in AI training couldn’t be higher. When language models are trained on content created with deceptive purposes, they don’t just inherit false information—they learn the sophisticated patterns that humans use to make deception appear credible.
By leveraging the largest record of human recognition of manipulative intent, AI companies can move beyond automated content analysis to understand the human psychology of deception. They can build models that recognize when content was created not just to inform, but to deliberately mislead.
The challenge of AI trust isn’t just technical—it’s fundamentally human. Understanding how humans attempt to deceive, and how other humans learn to recognize that deception, provides critical intelligence for building truly trustworthy AI systems.
Ready to enhance your AI’s ability to detect manipulative intent? Discover how Evaltas.ai’s comprehensive trust assessment platform, incorporating insights from the world’s largest manipulation detection dataset, can help you identify human patterns of deception in your training data.